
Meet an ISC Staff Member – Jason Lasky!
In the continuing series of profiles of some of our staff members, let’s get to know Jason Lasky, our Senior Account Manager!
Read postISC was recently involved in the troubleshooting and diagnosis of a DNSSEC-validation interoperability issue between BIND 9 and PowerDNS, where BIND is acting as a recursive server and PowerDNS is authoritative. The end result was that BIND marked the PowerDNS server as not supporting EDNS0. Since DNSSEC requires EDNS0 support, the PowerDNS server was no longer considered capable of answering DNSSEC questions, and therefore, the BIND server was not able to resolve the DNSSEC-signed domains served by the PowerDNS authoritative servers.
EDNS0 is a DNS extension that has been part of the protocol since 1999, and was originally described in RFC 2671 (since obsoleted by RFC 6981). BIND 9, like most other recursive resolvers, supports this extension, and implements logic to work around DNS servers and network devices that do not understand EDNS0, or that do not behave properly if they do understand EDNS0. BIND must handle competing objectives when processing query responses from an authoritative server. If BIND sends an EDNS0-enabled query to a server and does not get a well-formed answer, it will try sending the query again, only this time without EDNS0. If an answer arrives, then the server is considered to work - but not with EDNS0.
In the specific case described here, sometimes the PowerDNS authoritative server was returning an answer, but the response packet was malformed. Here is how the DNS packet flow transpired:
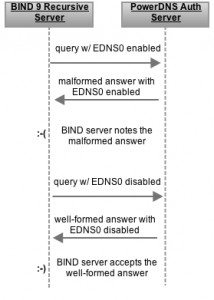
At this point, the BIND server has received a well-formed answer from the PowerDNS server - with EDNS0 disabled - so it marks the server as being able to answer, but this time without EDNS0.
Now, the main impact of marking a server as not being able to support EDNS0 is that DNSSEC requires EDNS0. This means that if all authoritative name servers for a domain are running PowerDNS and have the same error, then a DNSSEC-validating BIND 9 recursive server will not be able to resolve that DNSSEC-signed domain.
Further, this means that DNSSEC validation will no longer be possible for any of those servers’ DNSSEC-signed domains; if they are hosting thousands of domains secured by DNSSEC, all of them will become unresolvable.
From an administrative standpoint (i.e. what should the hapless DNS admin do about this), the solution is to either patch PowerDNS authoritative servers per the link above, or upgrade PowerDNS to version 3.3 RC. BIND administrators do not need to take any action unless they are running a validating recursive server that is already returning SERVFAILs due to marking the authoritative servers for the domains as EDNS0-incapable. In that situation, flushing the cache or restarting the server will restore normal service. It’s also particularly important in this case to be running a current version of BIND, as there have been bug fixes to cache management that are applicable to this situation - one in particular that ensures that an authoritative server’s EDNS0 capability (and other information) is refreshed after holding it for 30 minutes. Prior to this fix, authoritative server details were never discarded whilst the server was still being queried regularly.
Yet, while the actual fix for this situation is to upgrade the affected PowerDNS authoritative servers, it is theoretically possible for BIND to handle such partially-working servers better. One fix would be to always use EDNS0 when trying to get DNSSEC information from an authoritative server, rather than checking the server’s current status. This is what other resolvers (e.g. Unbound) do. The theory here is that if it works, then the user gets an answer; and if it does not work, it is no worse than not sending the query at all. Unfortunately, BIND 9’s current design does not make such information available when queries are sent. Changing the design to get around unusual situations like this would require a significant amount of engineering work, along with comprehensive functional and regression testing.
BIND could also try things such as requiring multiple failures, or shortening the time period before rechecking a server for EDNS0 support. These minor tweaks might help, and would not require major code changes. But they may also hurt in certain other cases, and again, would require significant retest effort. Ultimately, the BIND team decided not to make any code changes for this particular condition, since a fix exists for the PowerDNS server bug that is part of the problem, and this entirely mitigates the issue from a functional standpoint.
Significant changes are pending in the EDNS0 handling code for BIND 9.10 which will make BIND behave better in its handling of EDNS0 in general. This should certainly improve the situation, but highlights one of the issues with changing protocols, and changing existing implementations. Postel’s Law states: “Be conservative in what you do, be liberal in what you accept from others.” BIND - and indeed all other production recursive resolvers - must be fairly liberal in handling implementation quirks.
The unfortunate truth is that, because of the way DNS works, it is often the resolver server’s operator who has to deal with the impact of broken authoritative servers. Even when the authoritative servers are responding correctly, the effects of an earlier problem can persist in cache and may require special administrator (or script) intervention. Until we discover reliable techniques to handle for the majority of situations, we’re stuck muddling through occasional breakages. This ISC Knowledgebase article may help those who need to handle those situations.
What's New from ISC

In the continuing series of profiles of some of our staff members, let’s get to know Jason Lasky, our Senior Account Manager!
Read post
ISC is excited to announce the release of Kea 3.2.0, a new stable version!
Read post