
Meet an ISC Staff Member – Jason Lasky!
In the continuing series of profiles of some of our staff members, let’s get to know Jason Lasky, our Senior Account Manager!
Read postThe recently announced Meltdown bug is a serious vulnerability in Intel CPUs that allows malicious programs to indirectly read information held within the kernel of the operating system via a cache-timing side channel attack.
Mitigations for this bug have been released and (in Linux at least) these take the form of changes to the way that kernel memory is addressed whenever a “userspace” program is executing. This technique is known as Kernel Page Table Isolation (KPTI) – the kernel prevents the bulk of its address space from being accessed when not needed by swapping around the contents of the page table whenever there’s a context switch. However, that swapping comes at a price. Some benchmarks have shown performance impacts as high as 30% on heavy I/O workloads.
The question then, is what is the impact on a typical BIND 9 server? To test this I installed the latest version of Fedora Core 27 on a pair of 12-core (Xeon E5-2680 v3) Dell R430 servers connected via Intel X710 10 Gbps Ethernet. One of the systems was set up to generate traffic using dnsperf and the other was set up to serve the DNS root zone using the latest development branch of BIND 9.
Rather than swap between different kernel versions (which might introduce other performance effects) I installed the latest kernel (4.14.11-300.fc27.x86_64) and then started a series of tests enabling or disabling KPTI as needed using the nopti boot-time option.
Each test comprised multiple runs of dnsperf each lasting 30 seconds, with the query rate progressively ramping up between runs from 10k queries per second up to 360k. I then recorded the mean response latency as measured by dnsperf.
The first pair of runs (the first done with KPTI, the second without) gave a surprising result – the latency at high query rates was about 8% lower with KPTI than without, when it was expected to be higher! I’ve previously blogged and presented on the issues around getting consistent performance measurements with BIND 9 so there was clearly some unknown test variability at play here.
BIND 9 is a complicated piece of software, with its own multi-threaded task management system. On modern CPUs and with multi-queue network interface cards the task system, the NICs, and the O/S process scheduler all interact in ways that aren’t readily controlled. In particular it is extremely difficult (if not impossible) to balance the traffic so that each NIC queue (and hence CPU core) is receiving an identical number of packets. On these 12 core systems I typically find that perhaps 8 of the cores are working equally hard (albeit not at full capacity), with a couple working not so hard and a couple more working overtime.
The main feature that affects the balancing of incoming packets to CPU cores is called Receive Side Scaling (RSS). This uses a hash-based algorithm fed with the source and destination IP addresses and port numbers to decide which NIC queue the packet should be added to. On the X710 cards the hashing algorithm is re-seeded with a 52 byte random key at each reboot. Was this, perhaps, the main source of the variability?
Fortunately it’s possible to configure your own random seed for the receive flow hashing via the ethtool -X command. I therefore decided to perform two series of tests each using a different fixed random seed (denoted #1 and #2 in the graph). In total I performed 15 separate ramp up tests for each combination of flow hash and KPTI, with a reboot after every five tests. The graph below shows the average of the 15 runs for each of those four combinations:
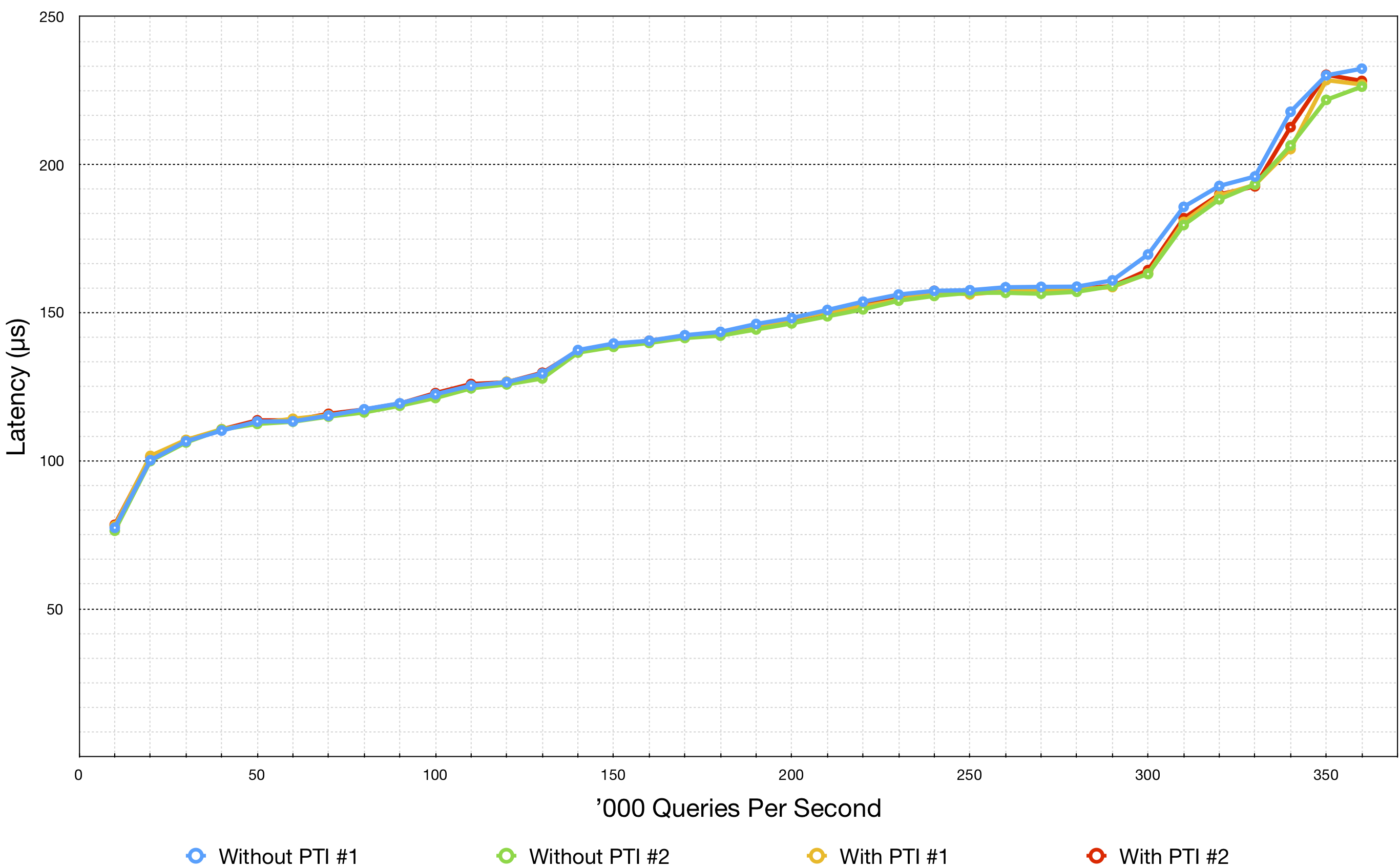
While (on average) the blue line graphing the combination of flow hash 1 without KPTI is slowest at high packet rates, the other three combinations generally perform the same as each other, albeit with more variability at the highest query rates. If KPTI were the sole cause of the different results, each KPTI measurement would have performed worse than its corresponding non-KPTI measurement with the same hash. Similarly, if the change of hash were the sole cause, we would not have expected the flow hash 2 to be faster than flow hash 1 in non-KPTI cases and slower in KPTI ones.
My conclusion therefore is that some other unidentified variable is responsible for the variability shown, and that the effect of that variable (or variables) is greater than that caused by the Meltdown mitigation patch (KPTI) which in turn appears to be relatively insignificant.
Please note however that these results are highly specific to our particular test environment. The CPUs in the test lab are quite recent and support the PCID and INVPCID extensions which help mitigate the overhead of swapping the page tables at each context switch. Your mileage may vary considerably, especially on older hardware without PCID support.
Sidenote: In preparing for this benchmark I did also measure the amount of time taken to compile BIND 9 with or without KPTI. A typical compile without KPTI took 269 seconds, and 273 seconds with KPTI. The extra four seconds was split 50:50 between “user” time and “system” time.
What's New from ISC

In the continuing series of profiles of some of our staff members, let’s get to know Jason Lasky, our Senior Account Manager!
Read post
ISC is excited to announce the release of Kea 3.2.0, a new stable version!
Read post