
All versions of Kea 2.6 are now EOL
Kea 2.6 reached the end of maintenance with the release of Kea 3.
Read postKea’s support for an optional external database backend is quite a useful feature. From the very early versions, Kea administrators have had the ability to store DHCP leases in either an in-memory database (written to a local disk) or, optionally, an external database backend. It can be easier to find and view lease information in a database than in a file, particularly when there are a lot of leases. Kea supports MySQL and PostgreSQL databases today. There is experimental support for Cassandra contributed by the community available in the Master branch.
Early adopters of Kea asked for the ability to manage a table of host reservations in a database, rather than in the DHCP server itself. These users found it was easier to integrate Kea with their provisioning systems if host addresses were in a database.
Kea 1.0 included support for retrieving DHCPv4 host reservations from a MySQL backend database.
Kea 1.1 will extend that to include:
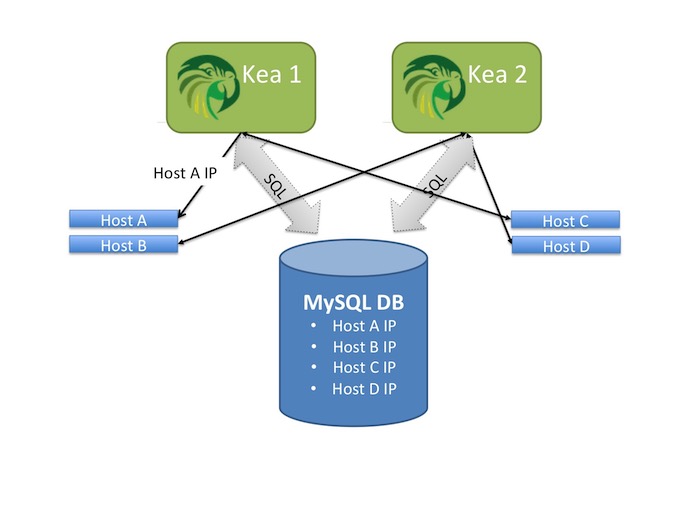
Host reservations diagram
Since we knew that a database could serve as lease storage for dynamic leases for a single Kea server, and shared storage for host reservations for multiple Kea servers, it seemed logical it could also serve as shared storage for dynamic leases for multiple Kea servers. We wanted to test a high-availability deployment of Kea using a database backend that replicated the shared lease state across multiple nodes. The goal was to determine how resilient the DHCP service would be to simulated failures of different components. We chose the Community Edition of MySQL Cluster for this test, but you could use another database (PostGreSQL is also supported), or another cluster technology. As one user posted on our user mailing list: “I used MySQL (percona) in a Galera cluster running on each DHCP server to achieve HA. Worked like a charm."
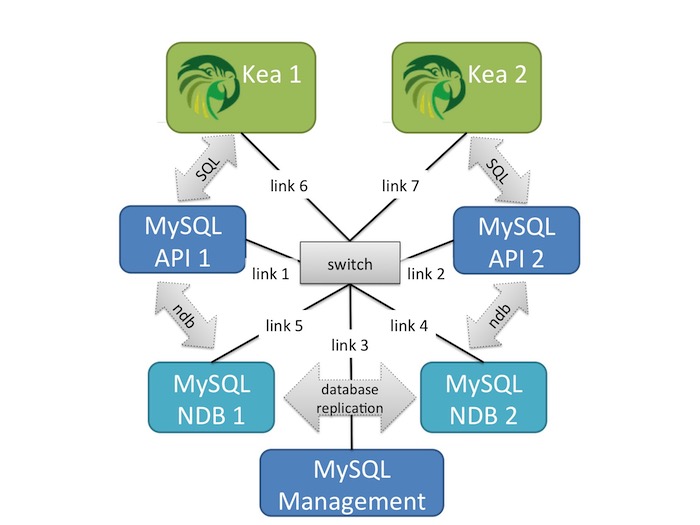
Logical diagram of test network
Our testing focused on two Kea servers connected to a single MySQL Cluster. Although everything is connected to the same network, Kea server 1 is configured to connect only to the MySQL API Server 1 and Kea Server 2 is configured to connect only to the MySQL API Server 2.
Aside from this difference the configuration for Kea Server 1 and Kea Server 2 are the same (subnets, options, etc). Both Kea servers have the same set of IPv6 addresses to hand out, (we tested exclusively with DHCPv6, but we don’t expect DHCPv4 to be any different) and are using the same method for deciding which address to hand out.
Separate Virtual Networks
We tested both ‘shared’ and ‘separate’ network connectivity scenarios. In the first scenario, the Kea servers and MySQL Cluster were all on the same network. This is the simplest scenario, and is what you might have if you installed the database backend on the same machine as the Kea server. We also tested a second scenario in which all components were on logically separate networks. This introduced slight delays, but for this test we did not inject significant delays. We didn’t see any difference in results, so we don’t report them separately below.
Traffic & Failure Simulation
The primary difference between setting up Kea to use a MySQL backend, and using a MySQL Cluster backend, is in the Kea schema set up script. Everywhere the script specifies ENGINE=INNODB; you must change it to ENGINE=NDBCLUSTER.
All twelve scenarios we tested with two Kea servers were successful. We verified that clients could still get addresses after a brief pause while the cluster stabilized after the ‘breakage’ we caused by disconnecting one or the other NDB node. 1 Kea Server 1 operating, disable one NDB node. Check to see if clients are still able to get addresses. (x2) PASS 2 Kea Server 2 operating, disable one NDB node. Check to see if clients are still able to get addresses. (x2) PASS 3 Both Kea servers operating, disable one NDB node. Check to see if clients are still able to get addresses. (x2) PASS 4 Both Kea servers operating, disable one NDB node, then re-enable that node. Check to see if Kea servers resume using both nodes. (x2) PASS 5 Both Kea servers operating, disable the Management node. Check to see if clients are still able to get addresses. PASS 6 Client with an address obtained from Kea Server 1 attempts to REBIND via Kea Server 2 while Kea Server 1 is offline. PASS 7 Client with an address obtained from Kea Server 1 attempts to RENEW via Kea Server 2 while Kea Server 1 is offline. A RENEW is normally unicast to the server that originally assigned the address and includes a serverID. A DHCP server should check the server ID of a RENEW request and only respond to requests for its own ID. So, this should not work if the original server is unavailable, and it did not work. PASS 8 Client with an address obtained from Kea Server 1 attempts to RELEASE via Kea Server 2 while Kea Server 1 is offline. As is the case with the RENEW test, Server 2 should not RELEASE and it does not, in compliance with the protocol. PASS
1 Throughout our testing we observed that if either of the MySQL nodes is disconnected, any Kea server connected via that MySQL node will stop responding to clients. Clearly the Kea server must have connectivity to a MySQL node, but it might be possible to add redundancy by enabling Kea to cycle through a list of SQL nodes, or to work with a VIP connected to multiple SQL nodes 2 All tests checking network failures showed that our cluster required a maximum of 34 seconds to get back to normal working after disconnecting any node. It should be possible to reduce the time required for the cluster to reconfigure with further tuning and experimentation. 3 We did try a more complex deployment model, with four Kea servers. In this test, we tried connecting multiple Kea servers to a single SQL node. The result was unsatisfactory. Multiple Kea servers handed out the same IP address. We ran out of time during this test to troubleshoot the problem and had to defer completing the work to prove a more complex deployment model. 4 Throughout our testing, we observed what appear to be race conditions as both Kea servers tried to allocate addresses from a shared pool in the same sequence. While this worked adequately well, except in the scenario where multiple Kea servers shared a single SQL node (#3), it is not optimal and probably decreases overall throughput. One option to mitigate this problem might be modifying the algorithm for selecting the next address.
Kea 1.0 servers will process a client’s packet exchange in the following sequence:
1 The client sends the first message (solicit or discover) 2 Both Kea servers will choose a candidate address. Each will then query the database to see if this address is in use or not. If it is in use the Kea server will choose another candidate address and try it. 3 Kea 1.0 chooses new candidate addresses by incrementing the previously used address and will continue trying addresses until it has exhausted the pool of available addresses. (In the future Kea may provide other choices for this feature.) 4 Once the Kea server has found an address that is not in use it will generate the reply to the client (advertise or offer). 5 When the client then attempts to claim that address by issuing a request, the Kea server will attempt to insert the address into the database. 6 If the database insertion succeeds then the address wasn’t in use and the Kea server will reply to the client, confirming the assignment. If the insertion fails then the address can’t be used (it may have been handed out by the other server).
When there are multiple servers inserting addresses we would expect some friction between the different servers as they may need to make more queries to find an available address. The amount of contention will depend on the topology of the network (when do the packets get to each server and to the SQL and DB nodes), the loading of the servers (how quickly they can respond to a given packet), and probably other factors.
There are some differences between the DHCPv4 and DHCPv6 protocols. While DHCPv6 allows sending a different address than was requested by a client in the Request message, DHCPv4 does not. Therefore in case of a lost race condition between Kea servers, DHCPv6 will be able to recover faster (by simply sending a Reply with different address) and DHCPv4 will take a bit longer (by sending NAK and causing client to go through the DORA process again).
Although Kea currently supports only a simple iterative allocator, we are considering implementing alternative allocation strategies in future versions.
Initial testing of Kea version 1.0 with MySQL Cluster v7.4.10 was conducted to determine whether Kea can be deployed in an Active/Active failover pair, without using DHCP failover. The tests were successful, showing that the database backend can provide the state replication needed for HA operation, whether the database backend was effectively local to the Kea server, or on a remote network.
This model has the potential to leverage database replication through the cluster to significantly improve overall resiliency of the solution.
We did not use Virtual IP Addressing (VIPs) in our test. It is possible that the Kea servers would not work with a VIP between them and the SQL nodes, because Kea expects a stable database IP address, but the VIP between SQL nodes and DB nodes should work, and is probably a recommended configuration. We recommend co-locating the SQL nodes with their associated Kea servers.
We identified several opportunities for additional testing and an opportunity for improving the efficiency of Kea in selecting available addresses in a shared lease backend deployment scenario. We are looking to extend Kea capabilities to support this deployment model in upcoming releases.
We are not specifically recommending the MySQL Cluster, because we didn’t test any alternatives, but if you choose to use a MySQL Cluster, you might try using the configuration we used because we know it works. We have put detailed instructions for how to set up the MySQL Cluster with Kea in our Knowledgebase.
If you are using a database cluster as a Kea backend, we would love to hear how you have it set up, and what success you are having. Please consider posting the details of your configuration on the Kea-users mailing list, or sharing them with us at info@isc.org.
We were helped in this test by Dale Rogers and James Fogg, who set up the MySQL Cluster and documented the setup in detail in MySQL Cluster set up for Kea 1.0.
DTR Associates
San Francisco, CA
info@dtrassociates.com
415-377-2880
What's New from ISC

Kea 2.6 reached the end of maintenance with the release of Kea 3.
Read post
In the continuing series of profiles of some of our staff members, let’s get to know Jason Lasky, our Senior Account Manager!
Read post